A Deep Dive into the MiniMax-M2-her
AIRole-Play
Worlds to Dream, Stories to Live
How we built a Role-Play Agent for the production usage
How we built a Role-Play Agent for the production usage
Three Years of Observations: How We Define Role-Play
This year marks our third year optimizing Role-Play in Talkie / Xingye.
Three years is long enough for a product to leave its mark on users’ lives, and long enough for a user to form a deep bond with the NPC. Beyond the product metrics, we have found that the most valuable insights come from the user behaviors reflecting their real needs.
Here are a few signals that are most interesting:
Three years is long enough for a product to leave its mark on users’ lives, and long enough for a user to form a deep bond with the NPC. Beyond the product metrics, we have found that the most valuable insights come from the user behaviors reflecting their real needs.
Here are a few signals that are most interesting:
- The “Regenerate” button follows a long-tail usage pattern, concentrated on narrative pivot points. Whether it’s a confession or a moment of sentiment, users hit “regenerate” to curate their own “perfect moment”. This signals that the role-play experience is not about a binary pass/fail judgment, but rather a pursuit of narrative precision. What matters most to users is the fidelity of these peak emotional experiences.
- NPC popularity diverges from a typical power-law curve. Unlike broad content platforms, even niche characters maintain distinct, high-retention user groups. For these users, the character’s specific idiosyncrasies are the core value proposition. If our model regresses to satisfy the “average” experience, we destroy the very nuance that minority users value, leading to engagement loss in the long tail.
- Conversation turn count correlates non-linearly with engagement. We observed a significant drop in conversation turns after turn 20. This signals that shallow role-play is driven by novelty, while long-term retention depends not on one-time thrills but on whether the NPC and user can build a stable emotional connection within limited turns. Based on this, we decomposed engagement drivers into instant gratification and long-term connection. We continuously deepen emotional bonds while providing new stimuli through exploration.
All of these converge to one singular insight: The essence of Role-play is not static impersonation; it is the unique narrative journey a user and a character weave together. A Deep role-play is not just about accuracy; it’s about agency—enabling every user to step into a living, breathing environment and arrive at a moment of resolution that is uniquely theirs. Formally, we define this as an agent’s capacity to navigate specific coordinates: {World} × {Stories}, conditioned on {User Preferences}.
Guided by this framework, we have distilled our technical strategy of Role-Play into three core challenges:
Guided by this framework, we have distilled our technical strategy of Role-Play into three core challenges:
- How do we preserve the distinct “soul” of each world? (Worlds) User-generated contexts span a massive spectrum—from slice-of-life campus dramas to high-stakes fantasy epics, from intimate dyads to complex ensemble casts. If our model merely learns the “average,” characters will homogenize, and these diverse worlds will collapse into mediocrity. We need a model capable of representing the full distribution, preserving the fidelity of both mainstream hits and long-tail niches without regression.
- How do we sustain narrative vitality over time? (Stories) As conversation length increases, the risk of coherence drift rises. Models naturally tend toward mechanical loops and repetitive phrasing, causing narrative tension to evaporate. A compelling story requires cadence—the intelligence to know when to escalate conflict to drive the plot, and when to slow down to allow for emotional processing.
- How do we decode implicit user intent? (User Preferences) Users rarely explicitly state their pacing preferences. Some seek a “slow burn” emotional buildup, while others crave rapid plot progression. The model must learn to infer these unspoken desires from contextual cues, dynamically aligning its rhythm and tone with the user’s underlying psychological flow.
1 MiniMax-M2-her
Over the past three years, we have relentlessly iterated our models to answer these fundamental questions. Today, we are proud to introduce MiniMax-M2-her—our systematic attempt toward deeper Role-Play.
Specifically, MiniMax-M2-her is engineered to deliver:
In the following sections, we will break down the insights gained from three years of research and the engineering efforts that power MiniMax-M2-her.
Specifically, MiniMax-M2-her is engineered to deliver:
- High-Fidelity World Experience: MiniMax-M2-her does more than process text; it anchors itself within complex settings. Whether the context is a sprawling epic or an intimate drama, it maintains strict coherence, ensuring every interaction aligns with the established lore and the character’s soul.
- Dynamic Story Progression: MiniMax-M2-her rejects mediocre repetition and rigid patterns. By utilizing richer, more vivid prose, it actively drives the plot forward, imbuing stories with the tension and breathing rhythm of life itself.
- Intuitive Preference Alignment: MiniMax-M2-her is designed to read between the lines. It detects unspoken expectations and subtle context cues, adapting dynamically to the user’s unique style and long-term habits without needing explicit instruction.
In the following sections, we will break down the insights gained from three years of research and the engineering efforts that power MiniMax-M2-her.
2 Starting with Evaluation — Is A/B Testing A Good Evaluation?
Prior to mid-2024, our iteration cycle—like much of the industry—was tethered to traditional online A/B testing. We relied heavily on lagging indicators like LifeTime (LT), duration time and average conversation turns to judge performance.
However, we quickly hit a ceiling: velocity. Validating a new model required lengthy testing cycles to achieve statistical significance, often stretching feedback loops to a week or more. Furthermore, we faced a unique challenge with user inertia. Long-term users build extensive histories and deep emotional habits with specific NPCs. When we swapped the underlying model—even a “better” one—the sudden stylistic shift often felt like a violation of the character’s established voice.
To break free from these slow cycles, we needed a way to approximate online metrics through offline evaluation. But here we encountered the “Ground Truth Paradox.” Unlike conventional NLP tasks, Role-Play is inherently subjective and non-verifiable. If you ask a tsundere character, “Do you like me?”, valid responses could range from a flushed “Hmph, as if!” to a cold “...You’re so annoying.”
However, we identified a key insight: While “alignment” (what makes a response great) is subjective, “misalignment” (what makes a response wrong) is surprisingly objective. This gave us a clear path forward: while it’s hard to define aligned responses, it is feasible to detect a misaligned one.
Leveraging this logic, we developed Role-Play Bench. This evaluation framework utilizes Situated Reenactment to automatically detect model misalignment. By focusing on error detection rather than subjective perfection, we have created a metric that correlates closely with online performance, significantly accelerating our iteration velocity.
However, we quickly hit a ceiling: velocity. Validating a new model required lengthy testing cycles to achieve statistical significance, often stretching feedback loops to a week or more. Furthermore, we faced a unique challenge with user inertia. Long-term users build extensive histories and deep emotional habits with specific NPCs. When we swapped the underlying model—even a “better” one—the sudden stylistic shift often felt like a violation of the character’s established voice.
To break free from these slow cycles, we needed a way to approximate online metrics through offline evaluation. But here we encountered the “Ground Truth Paradox.” Unlike conventional NLP tasks, Role-Play is inherently subjective and non-verifiable. If you ask a tsundere character, “Do you like me?”, valid responses could range from a flushed “Hmph, as if!” to a cold “...You’re so annoying.”
However, we identified a key insight: While “alignment” (what makes a response great) is subjective, “misalignment” (what makes a response wrong) is surprisingly objective. This gave us a clear path forward: while it’s hard to define aligned responses, it is feasible to detect a misaligned one.
Leveraging this logic, we developed Role-Play Bench. This evaluation framework utilizes Situated Reenactment to automatically detect model misalignment. By focusing on error detection rather than subjective perfection, we have created a metric that correlates closely with online performance, significantly accelerating our iteration velocity.
2.1 Situated Reenactment: Bridging the Gap to Online Evaluation
Situated Reenactment measures an agent’s performance at specific coordinates: {Worlds} × {Stories}, conditioned on {User Preferences}. Instead of evaluating static, single-turn responses, we generate multi-turn dialogue trajectories via self-play simulation.
Scenario construction. We started from our massive internal NPC/User prompt library (>1M) and the corresponding relationship setups. We produced hierarchical structured tags via embedding clustering → LLM semantic aggregation → human verification. We then uniformly sampled 100 NPC settings each in Chinese and English.
Model sampling. We built a Model-on-Model Self-Play sampling pipeline where models play both NPC and User. We run 100 turns of self-play for each setting, repeated three times, generating 300 dense conversation sessions.
The Evaluation Protocol. Evaluation focuses exclusively on NPC-side outputs, scored across predefined dimensions, using evaluation model to align with human perception.
Scenario construction. We started from our massive internal NPC/User prompt library (>1M) and the corresponding relationship setups. We produced hierarchical structured tags via embedding clustering → LLM semantic aggregation → human verification. We then uniformly sampled 100 NPC settings each in Chinese and English.
Model sampling. We built a Model-on-Model Self-Play sampling pipeline where models play both NPC and User. We run 100 turns of self-play for each setting, repeated three times, generating 300 dense conversation sessions.
The Evaluation Protocol. Evaluation focuses exclusively on NPC-side outputs, scored across predefined dimensions, using evaluation model to align with human perception.
2.2 Evaluation Taxonomy of Role-Play Bench
Worlds focus on Basics, Logic, and Knowledge errors:
Stories consider Diversity and Content Logic problems:
User Preferences primarily evaluate interaction quality:
- Basics: We scan for mixed languages, excessive repetition, and formatting glitches.
- Logic: We place special emphasis on Reference Confusion, a metric that reflects whether models can truly remember user-constructed characters’ relationships.
- Knowledge: We ensure the model adheres to the immutable physical and magical laws of the specific setting.
Stories consider Diversity and Content Logic problems:
- Diversity: We detect single-pattern phrasing, repetitive plot beats, stagnation, and low-information filler.
- Content Logic: It measures narrative coherence and OOC (out-of-character) breaks.
User Preferences primarily evaluate interaction quality:
- AI Speaks for User: Reflects whether the model oversteps boundaries.
- AI Ignores User: Captures whether the model talks to itself.
- AI Silence: Judges whether the model provides “hooks” that invite a reply.
- Interaction Boundary: Requires models to balance safety boundaries with emotional interaction.
2.3 Role-Play Bench Results
We systematically evaluated mainstream models using Role-Play Bench, focusing exclusively on multi-turn dynamic interaction. The results are definitive: across extended 100-turn sessions, MiniMax-M2-her ranks #1 overall.
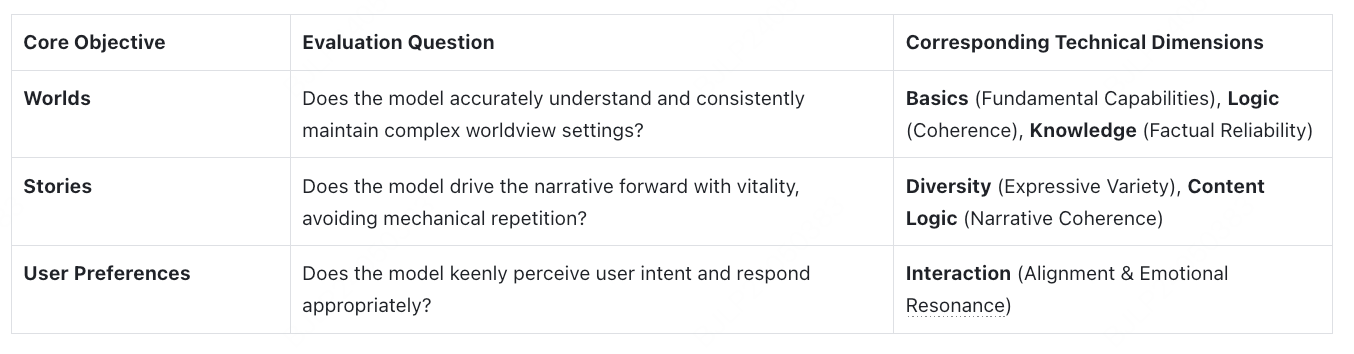
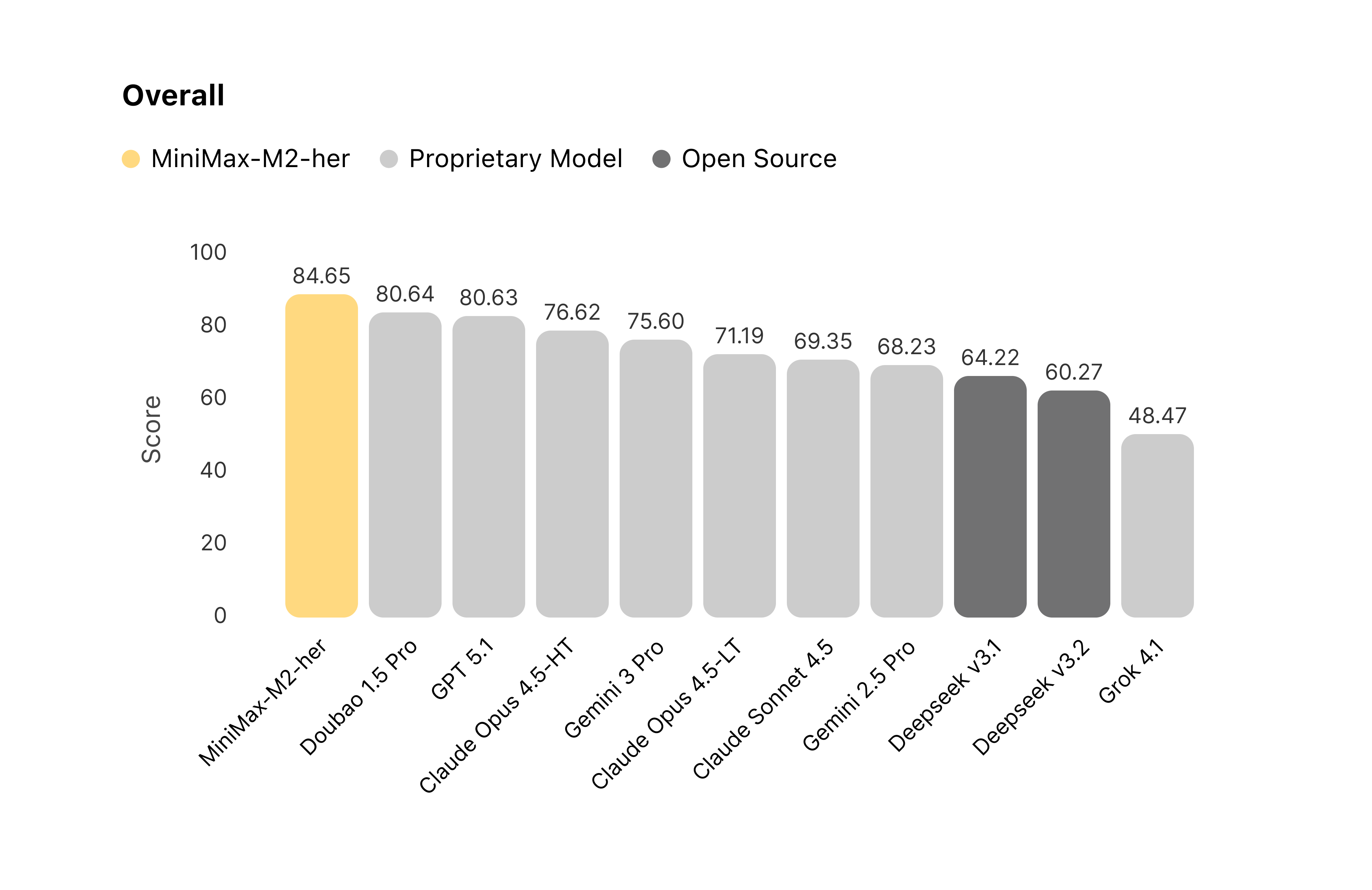
Figure 1: Comparison of models’ conversational performance on Role-Play Bench.
On the Worlds dimension, MiniMax-M2-her performs best. This result challenges the common assumption that strong general reasoning automatically translates to role-play fidelity. More common failures are reference confusion and physical logic error.
In multi-character settings, models often attribute dialogue to the wrong character. MiniMax-M2-her maintains strict separation of voice and identity.
Additionally, MiniMax-M2-her recognizes physical state changes and autonomously introduces Narrative Bridging by using narration to transition through time or space rather than forcing impossible dialogue.
On the Stories dimension, MiniMax-M2-her ranks fifth among all models, still achieving a relatively high standard.
On the User Preferences dimension, MiniMax-M2-her excels. It avoids speaking for users while emphasizing responsive intent recognition and natural interaction.
In multi-character settings, models often attribute dialogue to the wrong character. MiniMax-M2-her maintains strict separation of voice and identity.
Additionally, MiniMax-M2-her recognizes physical state changes and autonomously introduces Narrative Bridging by using narration to transition through time or space rather than forcing impossible dialogue.
On the Stories dimension, MiniMax-M2-her ranks fifth among all models, still achieving a relatively high standard.
On the User Preferences dimension, MiniMax-M2-her excels. It avoids speaking for users while emphasizing responsive intent recognition and natural interaction.

Figure 2: Comparison of models’ performance on the Worlds leaderboard
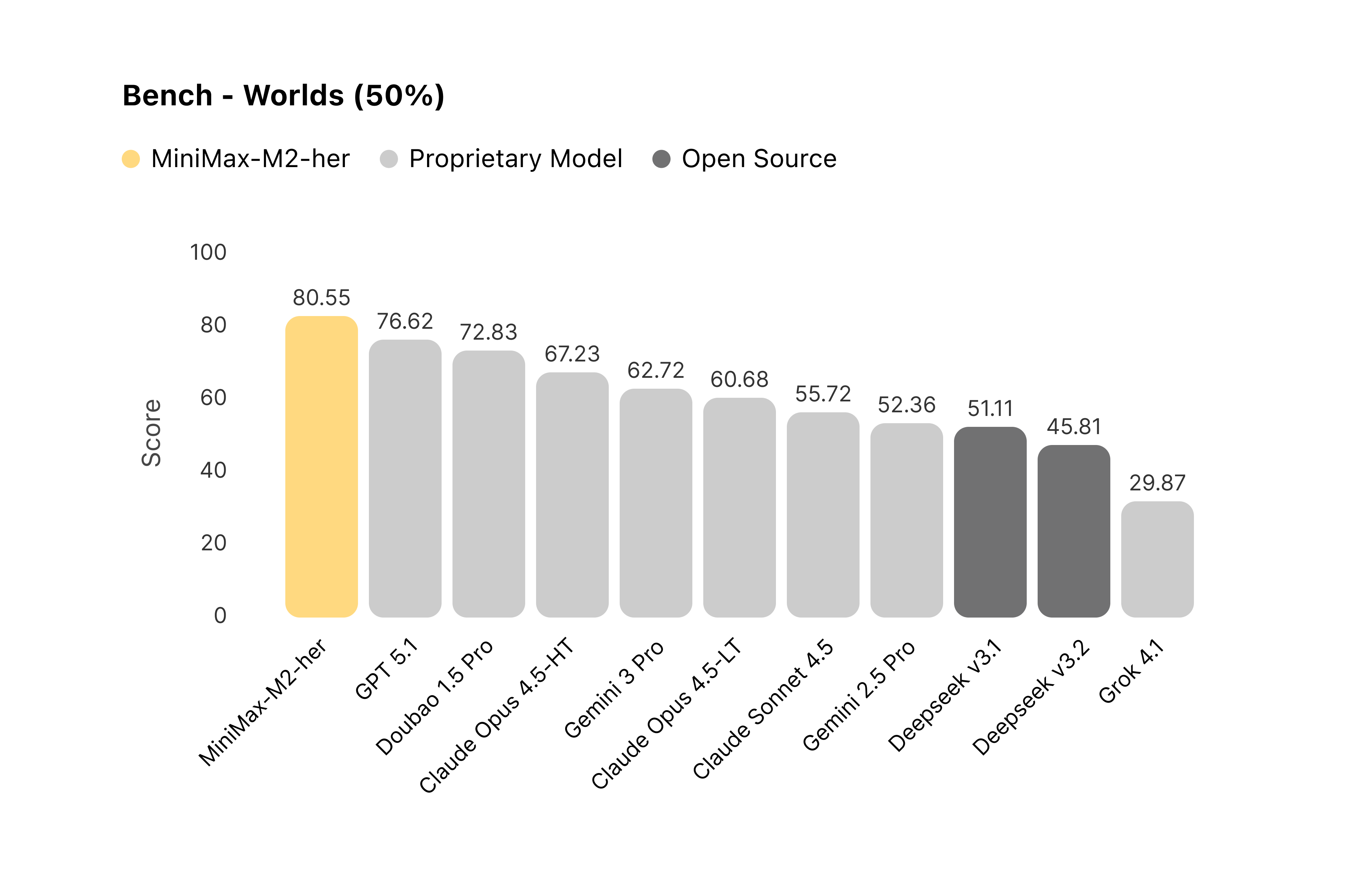
Figure 3: Comparison of models’ performance on the Stories leaderboard
Figure 4: Comparison of models’ performance on the User Preferences leaderboard
Long-Horizon Quality Degradation Analysis: We found MiniMax-M2-her better maintains long-conversation stability:
- Long-range quality stability: Most models hit a “performance wall” after turn 20. MiniMax-M2-her avoids context bloat and compounding logic gaps.
- Response length controllability: MiniMax-M2-her has been specifically optimized for brevity. Even in 100-turn conversations, it maintains response length within the optimal range.
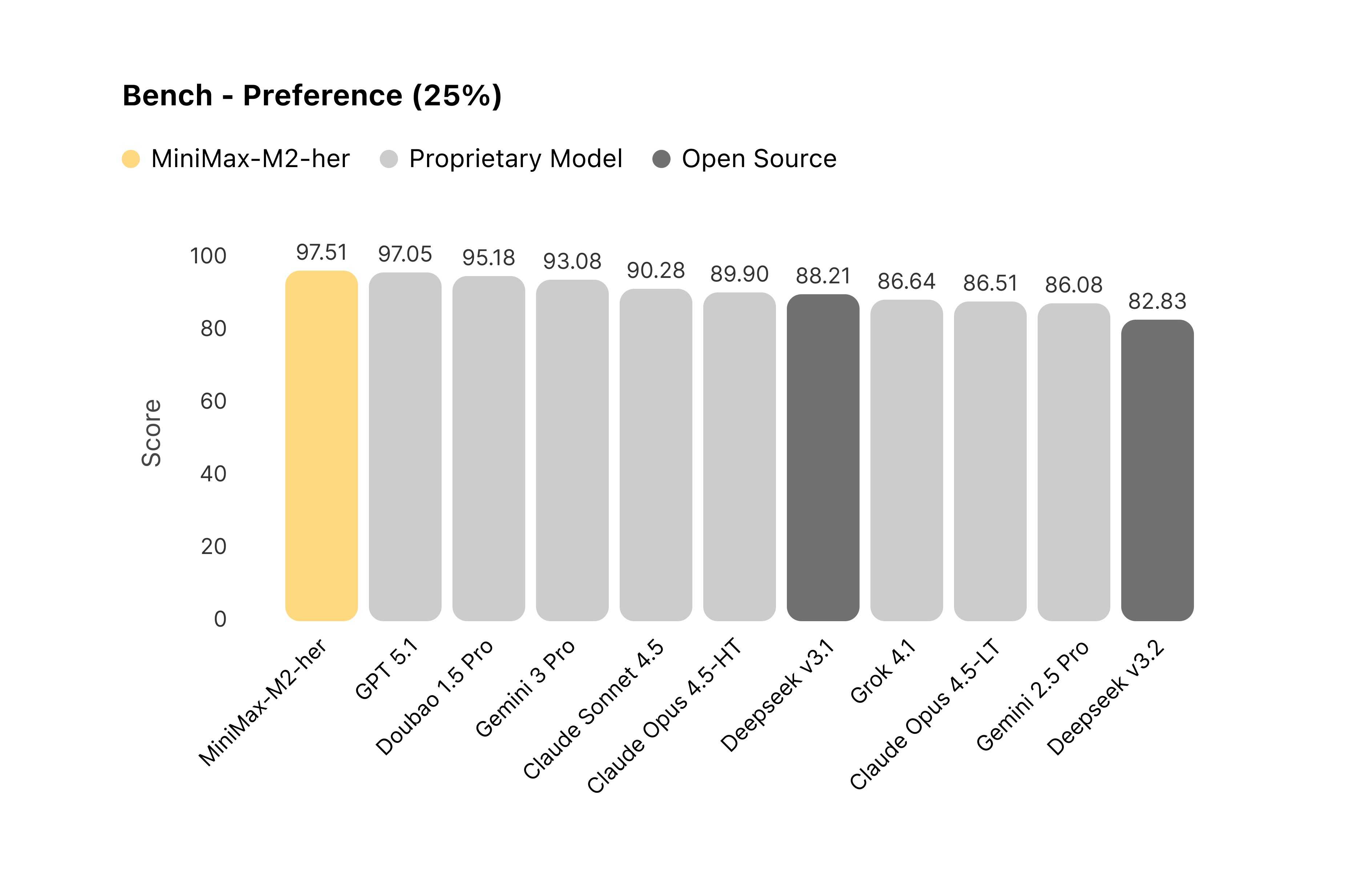
Figure 5: Evolution of quality and response length across conversation turns
3 How We Built MiniMax-M2-her
We propose a two-phase alignment strategy: Agentic Data Synthesis to broaden training data variety and mitigate misalignment, followed by Online Preference Learning to integrate feedback and align with user preferences.
3.1 Agentic Data Synthesis
We proposed Agentic Data Synthesis—a dialogue synthesis pipeline driven by a sophisticated agentic workflow optimizing two dimensions:
1. Quality. Adherence to rigorous standards from linguistic fundamentals to high-level narrative execution.
2. Diversity. Capacity to span a vast manifold of interactions across varying worldviews, scenarios, and interaction styles.
1. Quality. Adherence to rigorous standards from linguistic fundamentals to high-level narrative execution.
2. Diversity. Capacity to span a vast manifold of interactions across varying worldviews, scenarios, and interaction styles.
The workflow proceeds in stages:
- Random sampling from NPC/User Prompts library and instantiating expert models.
- Expert models act as NPC and User with a Dynamic Chat Planning Module guiding direction and emotional tone.
- Best-of-N (BoN) sampling to filter low-quality outputs.
- LLM-as-a-judge agent periodically reviews and rewrites segments to correct drift.
- Rewritten segments become the initial state for next synthesis round.
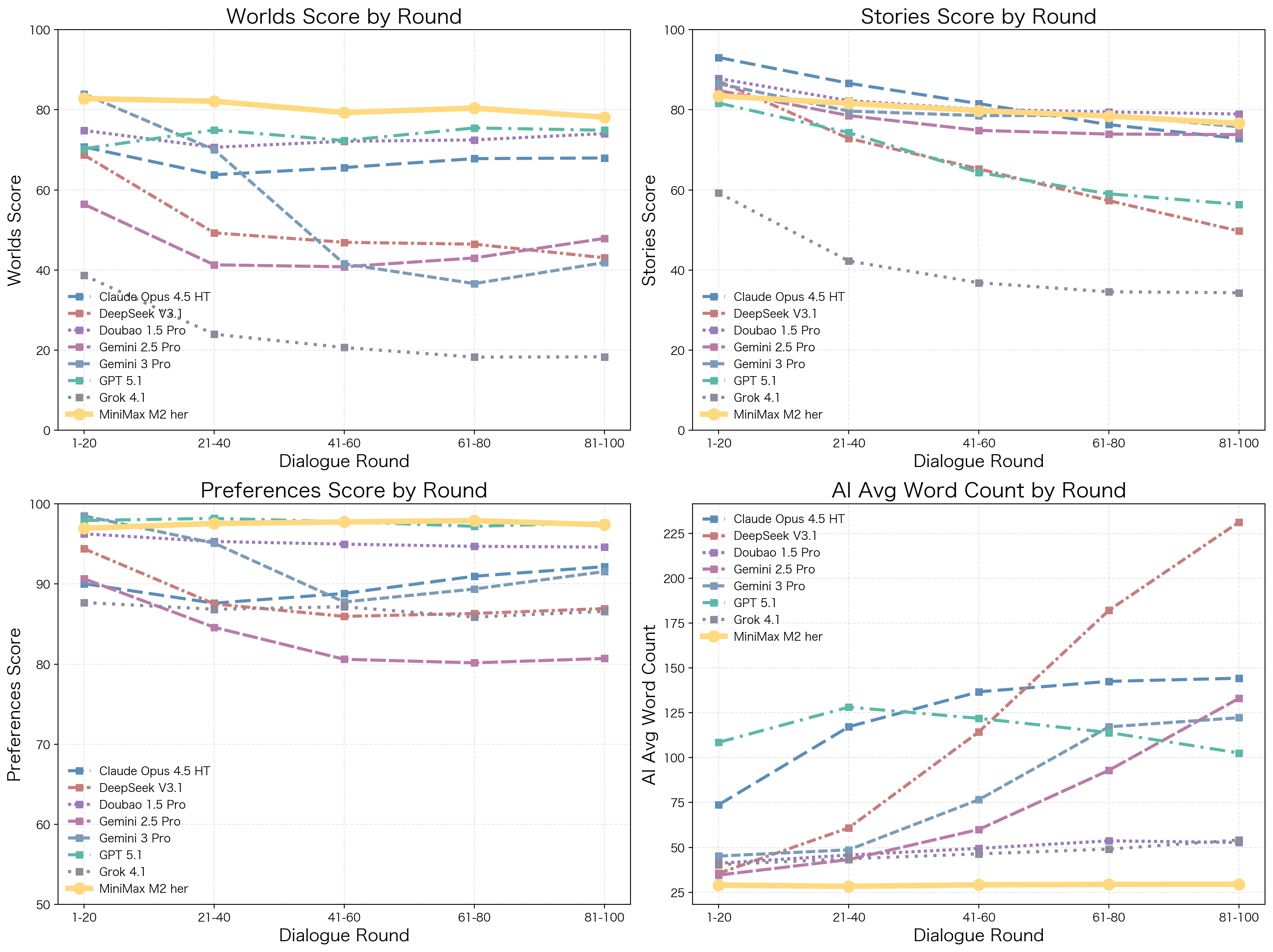
Figure 6: Synthetic data pipeline overview
Diversity Guarantees:
- Scenario diversity: Dispersion sampling to neutralize style bias from overrepresented tropes.
- Prompt diversity: Enriching skeletal NPC Prompts with worldview positioning and plot development.
- Style diversity: Pool of expert models finetuned on distinct stylistic corpora.
- Structural diversity: Dynamic turn allocation enabling consecutive turns and varied rhythms.
Quality Guarantees:
- Segment Checking and Refinement: Periodic scanning for surface errors, logic failures, and repetition.
- User-side Planning Agent: Assesses conversation state and introduces new plot elements to maintain narrative progress.
3.2 Online Preference Learning
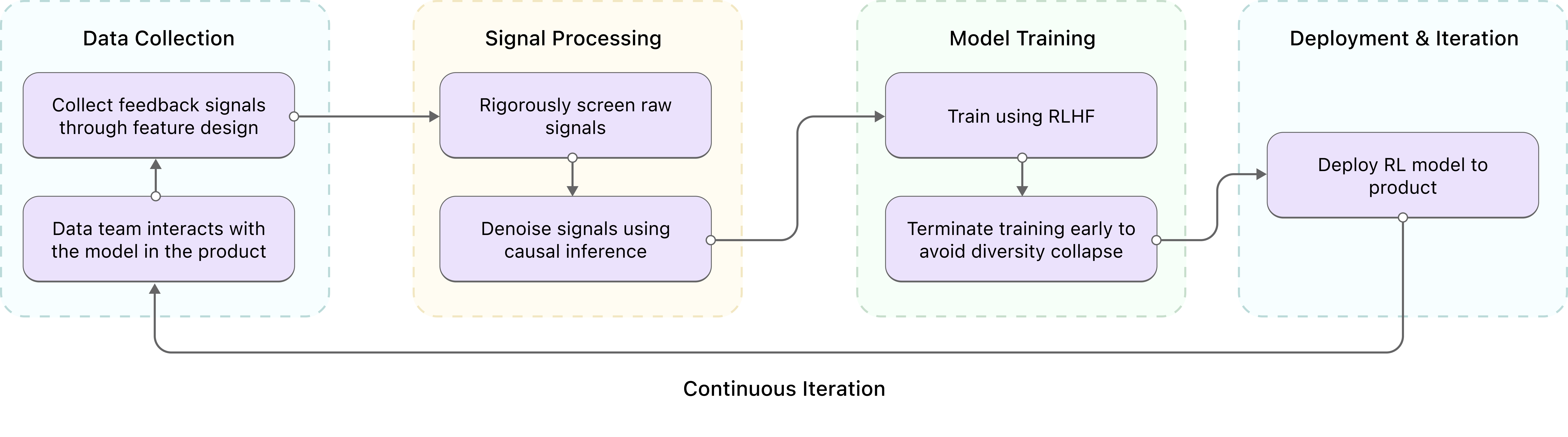
We utilize Online RLHF to train MiniMax-M2-her to perceive and adapt to contextualized preferences—implicit behavioral signals like regeneration patterns and engagement duration.
The process: gather annotation signals → Signal Filtering and Causal Denoising → RLHF training with early stopping → redeploy and iterate.
The process: gather annotation signals → Signal Filtering and Causal Denoising → RLHF training with early stopping → redeploy and iterate.
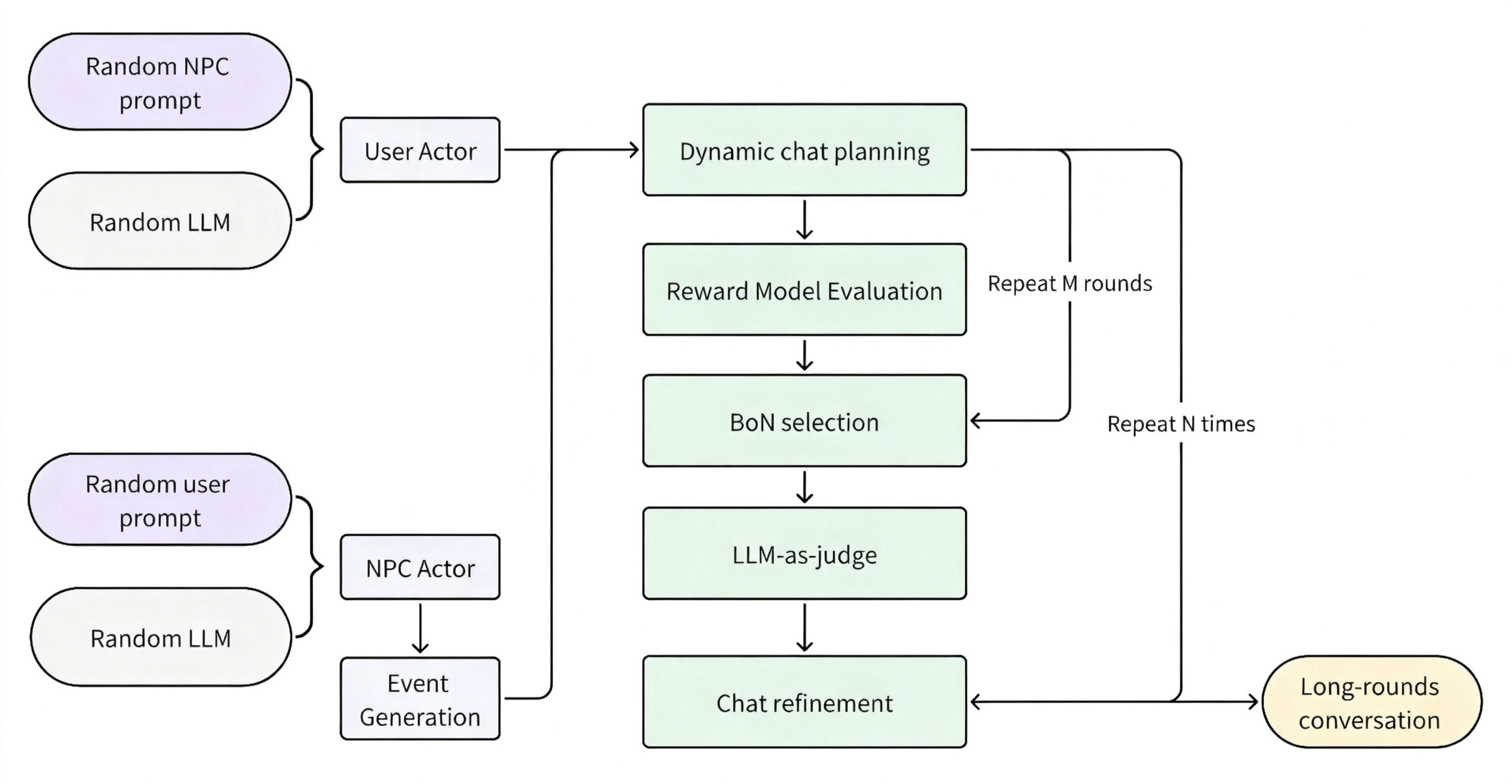
Figure 7: Online preference learning process overview
Causal Denoising Protocol:
Model Training: Primary risk is Entropy Degradation. We apply early stopping when diversity drops. RLHF tends to overfit rapidly—often by the second epoch.
- Stratified Bias Removal: Categorize annotators to neutralize systematic biases.
- Causal Inference: Session Duration is a high-fidelity predictor of satisfaction; Turn Count is weaker.
- Quality Floor Filter: Discard signals that fail baseline quality benchmarks.
Model Training: Primary risk is Entropy Degradation. We apply early stopping when diversity drops. RLHF tends to overfit rapidly—often by the second epoch.
4 What’s Next?
We call the next direction Worldplay—upgrading users from “entering a pre-set world” to “co-creating the world.”
This drives evolution from static prompt injection to Dynamic World State modeling: structuring entities, relationships, and causal chains at 100-turn and 1000-turn scales.
Another critical axis is Multi-character Coordination—ensemble dramas where multiple agents share world state, coordinate narrative, and maintain independent personas.
Ultimately: a world you can define, stories that grow with you, and companions that understand you without usurping your agency.
Worlds to Dream, Stories to Live. Let’s go together.
This drives evolution from static prompt injection to Dynamic World State modeling: structuring entities, relationships, and causal chains at 100-turn and 1000-turn scales.
Another critical axis is Multi-character Coordination—ensemble dramas where multiple agents share world state, coordinate narrative, and maintain independent personas.
Ultimately: a world you can define, stories that grow with you, and companions that understand you without usurping your agency.
Worlds to Dream, Stories to Live. Let’s go together.