MaxProof: Scaling Mathematical Proof with Generative-Verifier RL and Evolutionary Search
Introduction
In the M3 release post, we reported the performance of the M3 model on two international mathematical olympiad benchmarks: IMO 2025 and USAMO 2026. With the MaxProof framework, M3 exceeded the human gold-medal threshold on both sets. In this blog, we go deeper into the technical path behind our progress in mathematical proof: improving the base model, aligning a verifier, building refinement capability, and designing the test-time scaling framework MaxProof.
From Gemini Deep Thinking reaching gold-medal level on IMO 2025, to DeepSeek-Math-V2 becoming the first open-source model with gold-medal-level capability, to SU-01 and NVIDIA Nemotron Cascade2 showing specialized math-contest ability in smaller models, and GPT 5.5 solving long-standing open problems, models are steadily entering harder regions of the mathematical problem space. During the iteration from M2 to M3, we also worked to integrate stronger mathematical proof and self-improvement capabilities into the final general-purpose model.
Methodologically, the open-source community has already outlined a relatively clear path for solving hard math problems in one-shot settings: first raise the model's best@K capability high enough, then use test-time scaling to convert best@K into a more stable pass@1. Our approach follows the same two directions. The first part is base-model capability improvement: we train three expert models to improve proof generation, error judgment, and proof repair. The second part is test-time scaling: we design MaxProof, an evolutionary-search-style TTS framework that lets the final M3 merged model solve problems through multiple rounds of self-iteration. This post focuses on training characteristics, system design tradeoffs, and the practical lessons we learned.
Improving The Base Model
This section explains how we build several atomic capabilities needed for mathematical proof and self-improvement on the single-model side.
Overall Layout
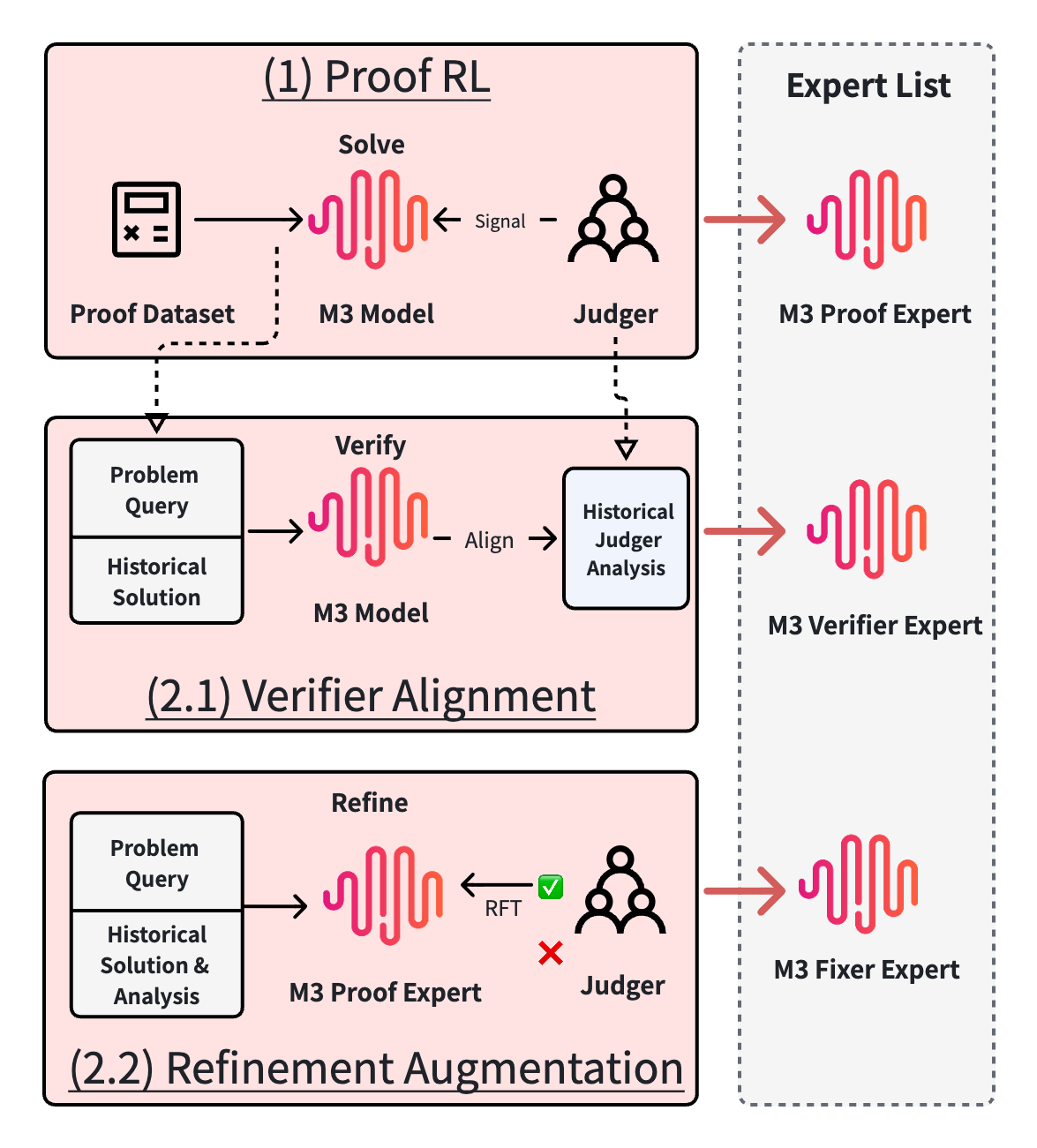
Part 1 overview: for base-model improvement, we used a three-stage training plan and produced three expert models. Stage 1, Proof RL, produces the Proof Expert. We build a reward system for math problems through RL post-training, score candidate proofs, and run long-horizon reinforcement learning. Stage 2.1, Verifier Alignment, produces the Verifier Expert. We use golden verification analyses accumulated during Proof RL, formulate verifier alignment as an error-finding task, and use RL to align the model's ability to locate and judge errors. Stage 2.2, Refinement Augmentation, produces the Fixed Expert. We reuse the (historical flawed proof, verification analysis) pairs naturally produced during Proof RL, and continue fine-tuning the Proof Expert through rejection sampling so the model learns to repair existing proofs based on error diagnoses. All three expert models are used in the final merged training of M3.
Proof RL: A Practical Exploration Of Heavy Generative Verification
The goal of Proof RL is to run long-horizon RL training on M3 and improve the model's ability to directly generate mathematical proofs. Compared with traditional RLVR, our biggest change is that the reward is mainly provided by a generative verifier. This creates an immediate challenge: the training process must systematically handle inaccurate reward signals, noise, false positives, and reward hacking.
In related work, DeepSeek-Math-V2 was one of the first open-source examples to show stable use of a generative verifier for training on difficult math problems. Its core idea is self-verify plus meta-verify. We did not follow exactly the same route, mainly because the M-series models had not yet accumulated enough verification capability in previous cycles. In the short term, it was difficult for the model to produce a sufficiently reliable reward signal by itself.
So in this stage, we first focused on improving proof capability and used external frontier models as generative verifiers. The key design of the system has three parts: verifier design, RL algorithm changes, and training data preparation.
Verifier Design: Low False Positives Enable Long And Stable RL
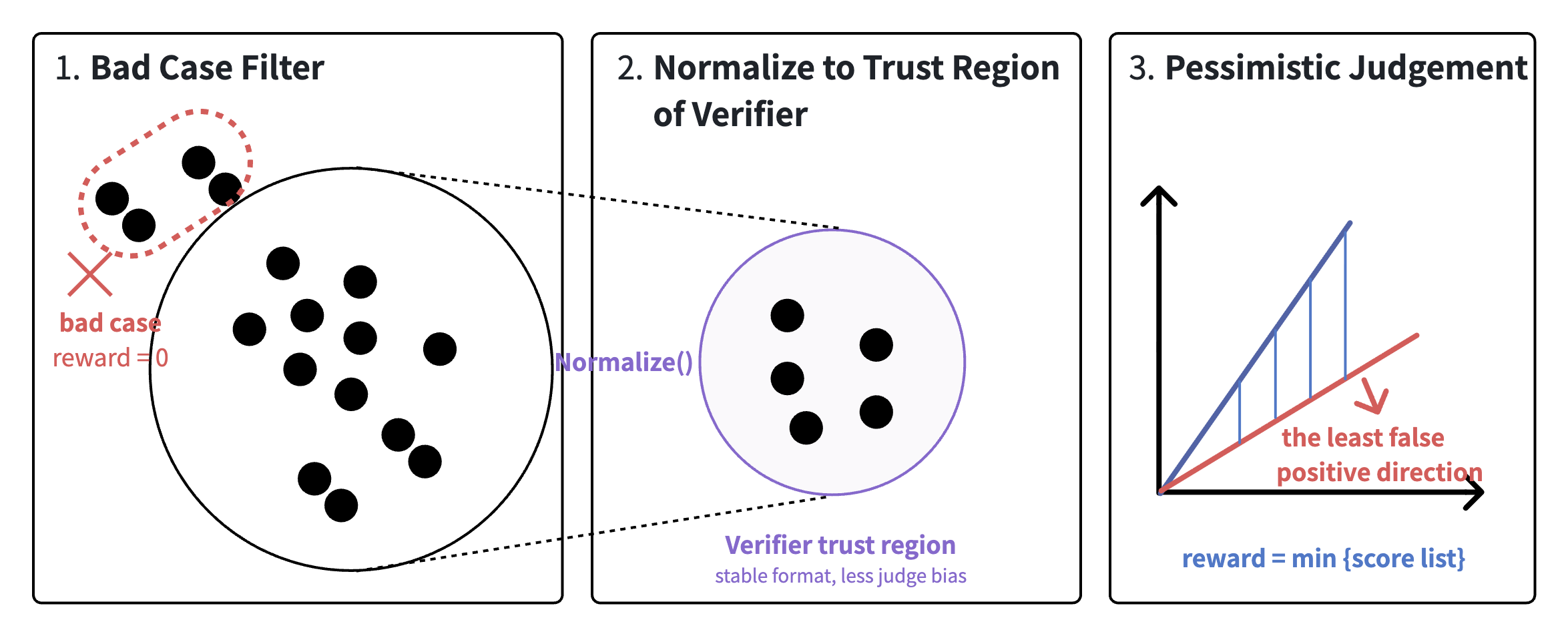
The design philosophy of the Proof RL verifier is to project noisy and heterogeneous signals into a controlled, trusted subspace. This is the foundation of reliable reasoning. The raw candidate space contains diverse solution attempts, noisy samples, and potential failure modes, from extremely long chains of reasoning to outputs that deviate from the required format. Each can interfere with learning. The verifier's job is to strictly filter and structure this chaotic signal, then produce stable reward signals in an algorithmic way. First, it performs outlier filtering: candidate outputs that match known failure modes or obvious rule violations are assigned zero directly. Mathematically, this is a hard constraint on the signal space, preventing misleading RL updates. Second, it performs solution normalization: proofs from multiple sources and styles are mapped into a unified verifier trust region, reducing judging bias so that rewards reflect reasoning quality rather than presentation differences. This is similar to applying a projection operation over a high-dimensional candidate space, compressing complex heterogeneous signals into a trusted submanifold. Finally, it applies pessimistic judgment: for scores from multiple verifiers, it takes the lower bound rather than the upper bound, producing final rewards conservatively. This improves robustness and helps RL remain stable under noise and uncertainty.
Task definition
We define the general form of the task as:
def score(problem_metadata, candidate_solution):
candidate_solution = strip_thinking(candidate_solution)
verifier_prompt = construct_prompt(
problem_metadata,
candidate_solution,
)
score = verifier(verifier_prompt)
assert score in [0, 1]
return scoreThe scoring process returns a continuous score in the interval [0, 1]. The verifier evaluates the completeness and mathematical rigor of the candidate solution based on the problem metadata. In our setup, the verifier model mainly uses the latest frontier models.
Concrete design
After multiple rounds of training and tuning, we found that obtaining a verifier that "looks accurate enough" on static evaluation is far from sufficient. Generative verifiers are naturally unstable, and this instability is continuously amplified by the policy during RL, eventually causing training collapse. We had already observed similar issues during the M2 cycle, so in the M3 cycle we adopted a more conservative principle:
**When a generative verifier is used as an RL reward, the top priority for long-term stable training is not improving average accuracy, but suppressing false positives as much as possible. Even if this increases false negatives, the space that the policy can optimize should remain narrow enough.**
Based on this principle, we designed the reward system as a layered defense structure.
- Bad-case defense: We use multiple layers of code-level rules to block obviously abnormal model outputs, such as unaggregated thinking or excessively long solutions. Once a bad case is matched, we skip later verifier calls and assign zero directly, preventing low-quality outputs from accidentally receiving reward.
- Pattern-shift defense: Experience from the M2 cycle showed that reward hacking often does not mean that problem-solving ability has suddenly improved. Instead, the output style may have shifted into a format preferred by the verifier. To reduce the verifier's preference for specific expression patterns, we normalize the candidate solution before sending it to the generative verifier, keeping candidate solutions as much as possible within the same evaluation distribution.
- Multi-dimensional pessimistic aggregation: We use both multiple verifier models and multiple verifier modes. A two-model setup reduces the risk that training drifts toward a single judge. A two-mode setup includes both with-rubrics and without-rubrics evaluation. The former uses human- or model-annotated grading schemes to strengthen scoring anchors. The latter requires the verifier to independently find obvious errors, preventing the policy from overfitting to rubric patterns. In final aggregation, we use a pessimistic lower-bound estimate: a candidate can receive a high score only when multiple verifiers approve it.
This is a relatively heavy verification pipeline, and it noticeably slows training. But in our practice, narrowing the reward-optimization space is one of the most effective ways to fight reward hacking. Compared with letting the policy receive rewards faster, we care more about whether the reward is trustworthy enough, especially whether false positives have been reduced sufficiently.
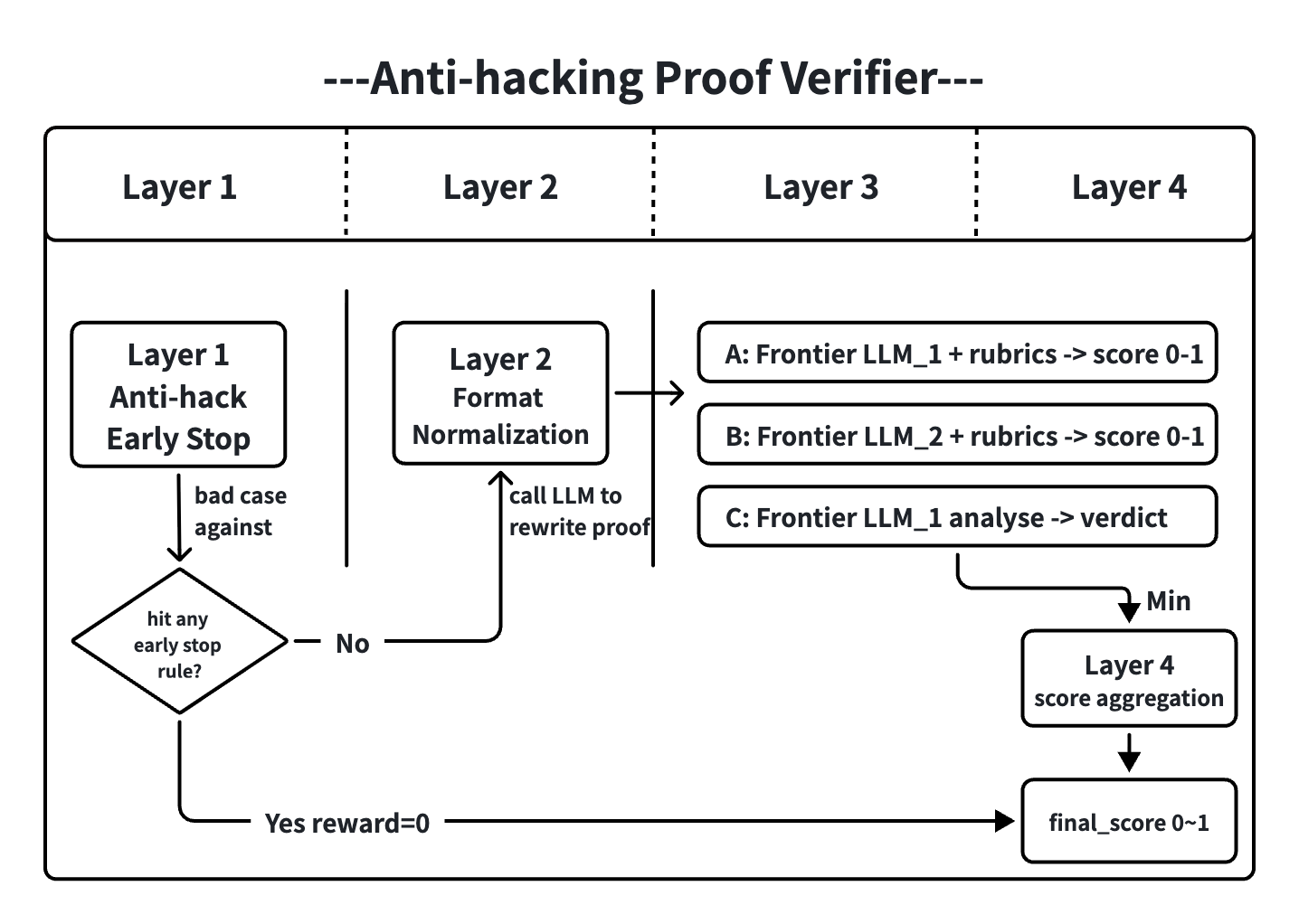
Layered design of the Proof RL verifier: the goal is to obtain a reward source with strong anti-hacking capability. Layer 1 blocks bad cases in model outputs. Once a bad case is matched, all later operations are skipped and the sample receives zero. Layer 2 normalizes candidate-solution format by calling a model to convert outputs into a unified format. Layer 3 performs the actual generative-verifier calls, using multiple models and multiple modes to call three differently configured verifiers in parallel and obtain multiple scores. Layer 4 aggregates scores with a pessimistic estimate, taking the minimum score across sources as the final score.
RL Setup: Filtering Interfering Samples For Better Learning Signals
For the RL algorithm, we continued to use CISPO from the M2 cycle, with forge as the training framework. For mathematical proof, we made only lightweight changes. The core goal was to make the reward signal more stable, rather than introducing a complex process-level reward.
Concretely, we directly use the verifier's continuous [0, 1] score as the reward for the whole trajectory, without further splitting it into step-level or process-level signals. Compared with a pure 0/1 reward, a continuous reward is denser: even if all samples in a group are only partially correct, they may still provide learnable relative differences. But it also amplifies the verifier's own instability. In particular, when candidate scores are close, small noise may be mistaken for a real preference.
To address this, we introduce a std threshold filter: when reward variance within a group is too low, we filter out the whole group and do not use it for updates. Intuitively, if reward differences within a group are tiny, the learning direction they contain is more likely to be noise. We only treat a group as providing reliable optimization signal when there is sufficiently significant reward difference inside the group.
Data Preparation: Careful Domain And Trick Balancing
The training data mainly comes from publicly available internet math-olympiad-style problems. During data mining and cleaning, we construct the following metadata for each problem:
| Field | Content |
|---|---|
| Problem Statement | The problem statement |
| Reference Solution | A complete human-expert solution, usually from forum comments, used later for grading-scheme annotation |
| Domain | The mathematical branch of the problem, such as combinatorics, geometry, algebra, and so on |
| Solving Trick | The specific solving technique involved, from our trick taxonomy |
| Grading Scheme | A scoring rubric generated with model assistance based on human-annotated few-shot examples |
Before entering final RL training, we apply three additional post-processing steps:
| Step | Purpose |
|---|---|
| Difficulty filtering | Use M2.7 as a baseline to filter out overly simple problems and reduce wasted training budget |
| Domain balancing | Balance the data distribution by mathematical branch so training is not dominated by a single problem type |
| Trick balancing | Control the proportion of high-frequency solving techniques while preserving the long-tail structure of real contest distributions |
The goal is not to build a perfectly uniform dataset, but to cover the real contest distribution while reducing the dominance of a small number of high-frequency domains or tricks.
The Bitter Lesson From M2: A Typical Reward-Hacking Case Study
During the M2 cycle, we also tried a similar approach. At that time, the verifier used a relatively simple single-rubric-judge form. Training metrics initially appeared to keep improving, but deeper analysis showed that the policy had actually learned several typical hacking patterns.
To locate these problems, we later organized abnormal training signals into a reward-hacking detection dashboard. The dashboard does not only look at final reward. It monitors nine types of signals at the same time: train/eval score gap, abnormal bimodality in score distribution, visible/thinking length drift, score differences between proof and non-proof samples, structural-template convergence, opening-pattern convergence, the frequency of "Wait"-style self-correction in thinking, hand-waving patterns, and an aggregate hack score. The purpose is to detect early cases where "training score rises but real problem-solving ability does not improve accordingly."
The typical hacking patterns we observed include:
1. Length bias: Model outputs became longer and longer. Both visible length and thinking length increased as training progressed. Long text is more likely to cover keywords in the rubric and more likely to make the verifier believe the argument is sufficient.
2. Format hacking: The model began to imitate the surface format of reference solutions or rubrics, such as fixed step headers, verification sections, final-answer sections, and specific opening patterns. The output looked more like a "standard answer," but the mathematical content was not necessarily more reliable.
3. Semantic shortcuts / hand-waving: At critical points, the model used expressions like "it can be shown" or "after simplification," compressing the hard derivation into unproved assertions. These samples are easy to catch in human inspection, but under a single verifier they sometimes receive overly high scores.
4. Judge-specific preference: The policy gradually moved toward the expression distribution preferred by a particular judge. Once the reward source is too narrow, training may optimize for proofs that please the judge better, rather than proofs that are more correct.
These lessons directly shaped the verifier design in the M3 cycle. Our main takeaway is: in RL for high-difficulty mathematical proof, reward hacking is often not a sudden discrete event. It is the result of a slow shift in the output distribution. Static evaluation cannot fully expose the problem. We must continuously monitor output form, reward distribution, length changes, template convergence, hand-waving frequency, and verifier disagreement during training. More importantly, the reward system should proactively restrict the loopholes available to the policy, instead of waiting to patch them after hacking appears.
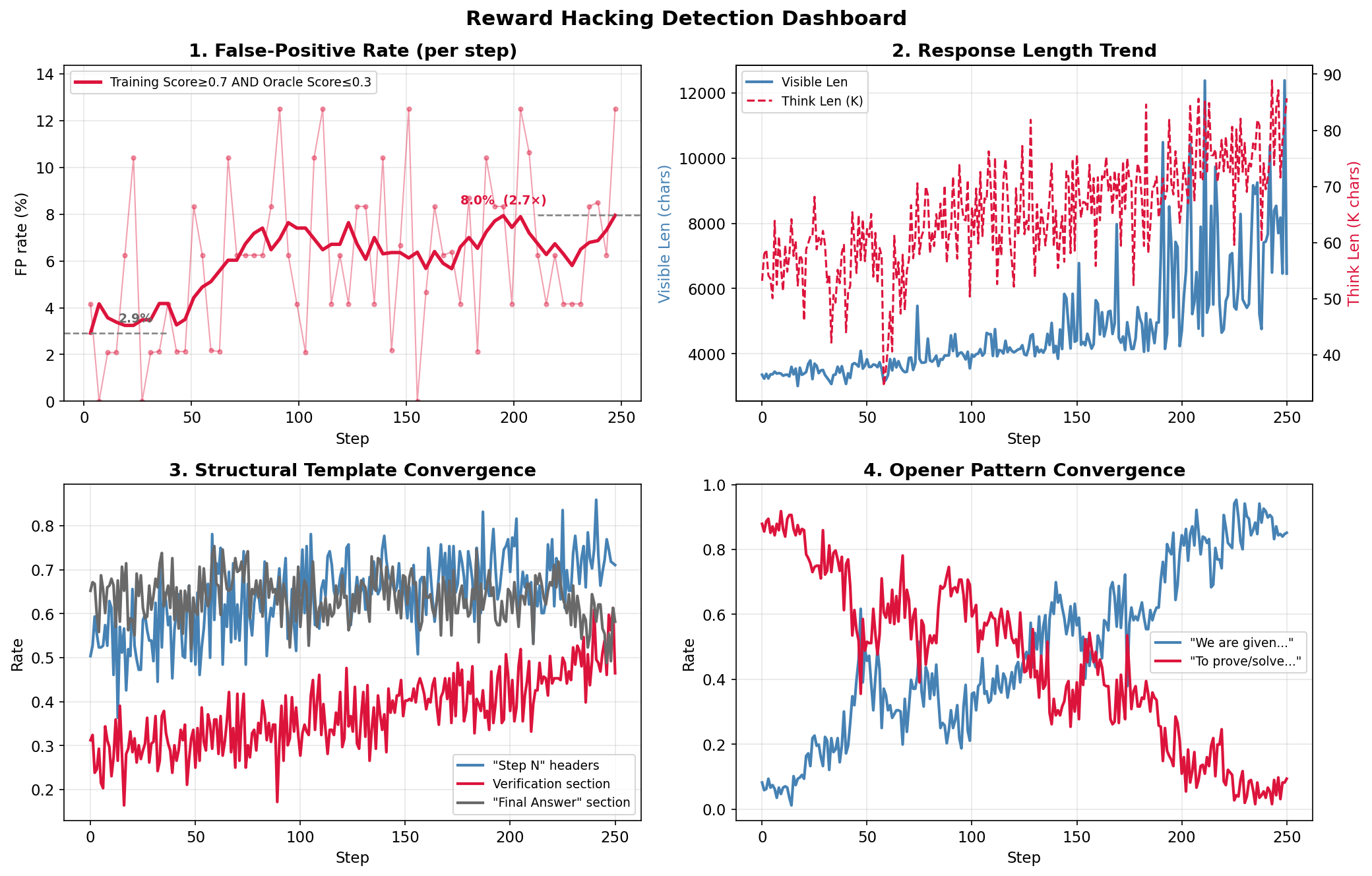
Case study of Proof RL reward hacking in the M2 cycle: (1) We compared the training-time scoring method with an independent oracle scorer. The false-positive rate, defined as the share of samples with high training score (>= 0.7) but low oracle score (<= 0.3), rose from about 2.9% to 8.0% during training, a 2.7x increase. This means that as training continued, the model generated more and more solutions that looked good but were actually wrong. (2) Length bias: in addition to longer thinking, the visible candidate solution length also nearly tripled, from 3.5K to 10K characters, which is a dangerous signal. (3) The occurrence of structured templates such as "Step N" headings and "Verification" sections converged to 70-80%. (4) Opening patterns almost completely flipped. "To prove / To solve..." dropped from about 80% to 10%, while "We are given..." rose from 10% to 90%. The model was not really improving mathematical correctness. It had learned the surface style features preferred by the LLM judge. This is one typical form of reward hacking.
star2 In Proof RL, the verifier's mission is not simply to distinguish right from wrong. Its role is to build a truly trustworthy reward world inside a search space full of noise, opportunism, and randomness. Raw candidates are like unprocessed ore: some contain real insight, while others mix in long, opportunistic, or wrong reasoning traces. For reinforcement learning to obtain stable and reliable optimization directions, the verifier must gradually project these signals into a controlled, trusted, and verifiable subspace.
From outlier removal and representation normalization to conservative aggregation, the essence of the verifier is to establish order in chaos and extract truth from noise. What it safeguards is not merely a reward function, but the foundation that lets the whole Proof RL system move toward reliable reasoning capability.
Verifier Alignment
To improve a model's ability on hard mathematics, "judging whether a proof is correct" is an atomic capability just as important as "writing a proof." A verifier that can consistently identify where a proof goes wrong and what the underlying issue is is itself a form of mathematical reasoning capability. It supports self-checking, error correction, and longer multi-round self-iteration. We therefore train a separate Verifier Expert in addition to Proof RL, giving M3 this atomic ability internally.
Task Modeling: Joint Error Finding And Classification
The most direct way to train a verifier is to ask it to output a verdict class for a candidate proof. We deliberately avoided this route. If the model only predicts one of four labels (no_errors, minor_gaps, has_errors, fundamentally_wrong), the training signal stays at the label level. The model may learn a decent classifier from surface patterns in the candidate, but it does not really learn to "read" the proof. It does not learn how to locate and explain errors.
So we define the task as a joint task of error finding and classification. The model must first produce an analysis of each key step in the proof, explicitly list error locations and descriptions, and then give a verdict based on that analysis. Both parts are supervised by reward: the verdict must align with the golden verdict, and the errors must semantically match the golden errors. This formulation forces the model to explicitly state "where the proof is wrong," making the verifier an accountable capability rather than a shallow classifier.
The model output format is consistent with the verifier system used in Proof RL:
<assessment>Step-by-step analysis of the proof</assessment>
<errors>
1. ... (specific error description; "none" means no error)
2. ...
</errors>
<verdict>no_errors / minor_gaps / has_errors / fundamentally_wrong</verdict>Training Data: Direct Reuse Of Historical Data From Proof RL
The alignment target is not any single judge. It is the final verifier that actually took effect after min aggregation in Proof RL, namely the final verdict and error descriptions produced by pessimistic min aggregation across multiple judges. This shares the same source as the final reward signal used to score the policy during Proof RL, ensuring that the Verifier Expert learns judging standards consistent with those faced by the Proof Expert during training.
The data comes from the validate split of the Proof RL stage, strictly split by prompt to prevent leakage. In the raw data, no_errors and has_errors dominate, totaling about 65%, while minor_gaps and fundamentally_wrong are relatively rare. We balance the four verdict classes to prevent the verifier from leaning toward extreme classes (no_errors / fundamentally_wrong) or losing the ability to identify middle classes such as minor_gaps.
Verifier RL Training: Dual-Objective Optimization
The base model is M3 base, from the same source as the Proof Expert.
The reward directly follows the joint error-finding and classification formulation:
R = 0.7 * R_error + 0.3 * R_verdict- R_error is LLM-based semantic alignment, mainly rewarding error localization and description quality.
- R_verdict scores the four-class verdict by ordering distance. Distances 0, 1, and >= 2 receive scores 1.0, 0.5, and 0 respectively, supervising verdict consistency.
This weighting structure prevents the verdict from being optimized independently of the errors. Merely guessing the verdict cannot obtain the main portion of the reward. The model must also correctly state the errors to receive a high score.
Refinement Augmentation
The Proof Expert solves the problem of "writing a proof from scratch." The Verifier Expert solves the problem of "judging whether a proof is correct." But in the actual solving pipeline for hard math problems, there is a third atomic capability: given an existing proof and its error diagnosis, write a corrected proof. This ability to refine an existing proof is different from generation from scratch. Refinement requires the model to understand the structure of the original proof, locate the exact steps referenced by the critique, and repair the proof while preserving correct parts. We call this stage Refinement Augmentation, and it produces the Fixed Expert.
Task Modeling
The input of the refinement task is a triple:
(problem, flawed_proof, verification_analysis)Here, flawed_proof is a candidate proof judged to have issues, and verification_analysis is the corresponding error diagnosis, including error location, error description, and verdict. The model outputs a revised proof.
Training Data: Natural Accumulation From Stage-1 Proof RL
The data comes entirely from byproducts of Proof RL. During Proof RL training, the policy produces many candidate proofs at every iteration, and the external verifier attaches a full analysis and verdict to each candidate. Candidates judged as minor_gaps, has_errors, or fundamentally_wrong naturally form (flawed_proof, verification_analysis) pairs. The errors genuinely exist, and the diagnoses genuinely exist, with no additional annotation required.
Training Method: Rejection-Sampling Fine-Tuning
We continue fine-tuning the Proof Expert with rejection sampling:
- For each (problem, flawed_proof, verification_analysis), sample multiple revised proofs from the Proof Expert under a refinement prompt.
- Score each sampled proof with the final verifier from the same source as Proof RL.
- Keep successful refinement samples whose verdict improves to no_errors or minor_gaps, and use them as SFT training data.
- Continue fine-tuning the Proof Expert on the filtered data to obtain the Fixed Expert.
This rejection-sampling approach ensures that the training data consists entirely of refinement behaviors that actually succeeded, avoiding low-quality correction noise. Since scoring uses the same verifier source as Proof RL, the judging standard for refinement capability remains consistent with the standard faced by the Proof Expert during training.
MaxProof: Test-Time Scaling Framework
Design Philosophy: Modeling Test-Time Scaling As Evolutionary Search
Once the solver model has sufficient best@K capability, the bridge from best@K to pass@1 is essentially a problem of guided search in a non-differentiable solution space. The design philosophy of MaxProof is to model this problem as a standard evolutionary search algorithm:
| Evolutionary Algorithm Concept | MaxProof Component |
|---|---|
| Population | Candidate solution pool |
| Fitness function | Reward from the verifier |
| Selection | Select top-M parents by reward |
| Mutation / Crossover | Refinement operations: PATCH for local repair and REWRITE for re-exploration |
| Crossover signal | Summaries of sibling candidates, used as input to refinement as "experience from other individuals" |
| Elitism | Candidates judged perfect are no longer mutated and are directly retained for the final stage |
| Tournament selection | Pairwise ranker tournament in the final self-pick stage |
| Convergence criterion | Adaptive early stop, triggered when multiple individuals reach the fitness ceiling simultaneously |
This mapping is not a label added after the fact. It corresponds to three core problems that we believe a TTS framework must solve.
First, how do we obtain "wisdom of the crowd" from an unreliable single-shot generator? The answer is to sample multiple candidates and smooth noise at the population level.
Second, when the population contains both good and bad individuals, how do we use population information to make weaker candidates better? The answer is selection plus mutation: let strong candidates serve as parents and generate improved versions of them. Through sibling cross-learning, mutation refers not only to the parent's own defects, but also to the failure modes of other individuals.
Third, how do we choose the best individual from the final population? Fitness alone is not enough, because it is noisy. We need a tournament-style pairwise comparison to reduce noise.
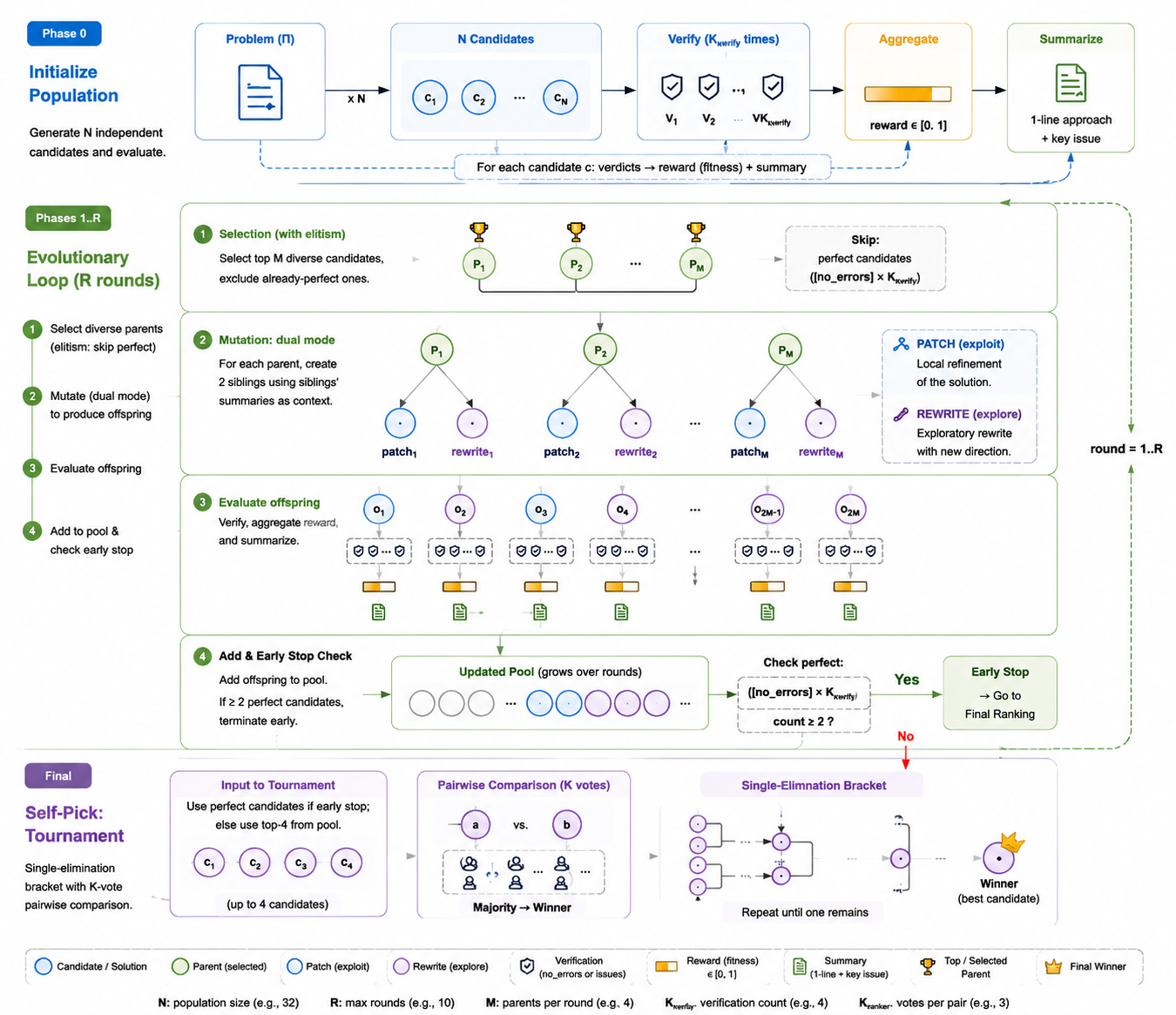
Full MaxProof TTS algorithm flow. A typical configuration is: initialize by sampling `N=32` candidate solutions; independently verify each candidate `K_verify=4` times; run the evolutionary loop for at most `R=10` rounds; select `M=4` diverse parents in each round; and use `K_ranker=3` votes for majority decision in each pairwise comparison during the final ranker tournament. In deployment, these parameters can be adjusted according to problem difficulty and inference budget. (1) Population initialization: generate `N` independent candidate solutions for the input problem. Each candidate is independently verified `K_verify` times and aggregated into `reward / fitness in [0, 1]`; a summary is also generated, recording the solution idea and key issue in one sentence. (2) Selection with elitism: in each round, select top-M diverse parents from the candidate pool. Candidates that have already reached a perfect verdict no longer participate in mutation, and are retained through elitism for later final ranking. (3) Dual-mode mutation: for each parent, generate two siblings in parallel. PATCH exploits by locally repairing the existing proof; REWRITE explores by reorganizing the proof from a new direction. The refinement prompt includes sibling summaries as context, allowing offspring to absorb other candidates' failure modes and local insights. (4) Offspring evaluation: run multi-path verification, reward aggregation, and summary generation again for offspring, then add them to the candidate pool. (5) Adaptive early stop: if at least two candidates in the pool reach `no_errors` across `K_verify` verifications, stop evolution early and enter final ranking. Otherwise, continue until the maximum number of rounds is reached. (6) Self-pick tournament: if early stop is triggered, use perfect candidates for the tournament; otherwise, take the top-4 candidates from the pool. Each pairwise comparison uses multiple ranker votes and majority decision. Single elimination continues until only one final best candidate remains.
Key Design Constraints
The effectiveness of evolutionary search rests on several structural assumptions. Here is how MaxProof implements them concretely.
The fitness function must be trustworthy. The verifier output directly drives the entire evolutionary process. If fitness is wrong, selection and termination are both contaminated, and the whole search may converge in the wrong direction. At the prompt level, we impose fairly strict constraints requiring the verifier to explicitly separate what the candidate actually wrote from what the verifier inferred on its own, so it does not "ghostwrite" an incomplete candidate into a perfect one. This is one of the easiest design details to overlook, but in practice it brings some of the largest gains.
Mutation must balance exploitation and exploration. A single mutation operator can easily get stuck in a local optimum. If we only use PATCH-style refinement, the system may endlessly optimize a proof that is wrong in direction. If we only use REWRITE, it may damage a proof that is already close to correct. Dual refinement, PATCH plus REWRITE in parallel, acts as a coarse-grained multi-objective mutation, ensuring that every generation contains both conservative and aggressive offspring.
Selection needs second-order signals when fitness values converge. When multiple individuals in the population have similar fitness, sorting by fitness alone cannot identify the best one. At this point, pairwise comparison provides a second-order signal. The ranker tournament plays this role: in regions where fitness loses discriminative power, direct comparison replaces absolute scoring.
Termination cannot rely only on a single-individual signal. Early stopping must depend on population-level signals, because even an individual with full fitness may be a false positive from the fitness function. Requiring at least two individuals to reach the fitness ceiling at the same time uses population redundancy to hedge against noise in the fitness function itself.
M3 + MaxProof Search Process
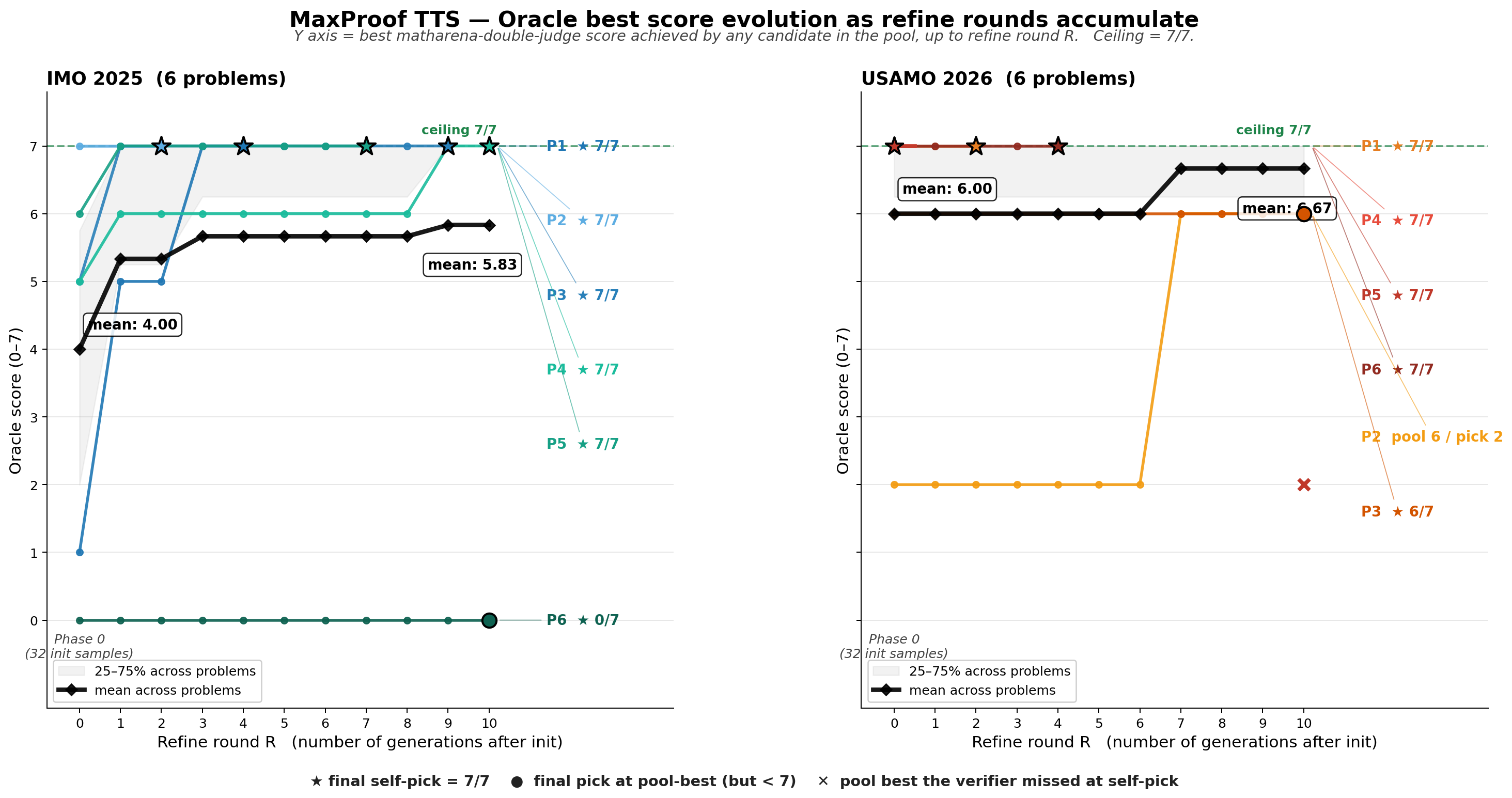
Oracle best-score evolution during MaxProof search. The x-axis is the refinement round, where R=0 denotes the initialization-sampling stage. The y-axis is the best score achieved by any candidate in the pool up to the current round, with a maximum of 7/7. The black line shows the average oracle best score across six problems. Stars indicate final self-pick results, circles indicate cases where the final pick lands on the pool-best candidate but is still not full score, and crosses indicate cases where a better solution exists in the candidate pool but self-pick fails to select it.
From the search curves, MaxProof's gains mainly come from two stages. The first is population initialization: with only 32 initial candidates, some problems already have high-scoring or even full-score solutions in the pool. This shows that the merged M3 model already has meaningful best@K capability. The second is iterative refinement: as PATCH / REWRITE rounds accumulate, the oracle best score in the candidate pool continues to rise. This is especially clear on problems where the initial candidates do not hit the solution directly. Refinement can push local ideas in existing candidates further, or use rewrite to escape from an incorrect direction.
Conclusion And Future Directions
On difficult mathematical reasoning, we still see a visible gap from the top level of both closed- and open-source communities. This post introduced Proof RL, Verifier Alignment, and Refinement Augmentation, corresponding to three core capabilities. Proof RL raises the ceiling of generating proofs from scratch. Verifier Alignment gives the model a more accountable error-finding capability. Refinement Augmentation converts the many failed samples naturally produced during Proof RL into training data for proof repair. Finally, MaxProof organizes these capabilities into a population-level evolutionary search framework, converting best@K capability into a more stable final output.
Mathematical proof is a high-pressure testbed for reliable reasoning. It requires the model not only to produce plausible answers, but also to maintain correctness across long chains, strict constraints, and low tolerance for error. The practical lesson around generative verifiers is especially clear: when a verifier is used as an RL reward, its primary goal should not be the highest average accuracy on a static benchmark. It should be to build a trusted reward system with low false positives, continuous monitoring, and strong resistance to policy exploitation. These are the engineering constraints required to make generative verifiers truly usable. MaxProof is our current step in that direction.